本文共 2089 字,大约阅读时间需要 6 分钟。
目录
Abstract
本文提出一种自由使用声码器的语音转换方案,该方案使用WaveNet和非平行语料进行训练,使用WaveNet将 Phonetic Posterior Grams(PPG)直接映射到波形样本,以此来代替中间特征的处理。这样,我们避免了由声码器和特征转换引起的估计误差。 此外,由于PPG被假定为与说话者无关,因此所提出的方法还减少了基于WaveNet声码器的方法中的特征不匹配问题。
1 Introduction
- 存在的问题: 使用传统的参数声码器,在语音特征提取和语音合成阶段会产生伪相,即明显人工合成的声音。WaveNet能够合成高质量的语音,但会产生生成语音与输入特征错误匹配的情况,这会导致合成的语音中有噪音的情况。
- 解决方案: 提出一种使用WaveNet在非平行语料条件下的无声码器的语音转换方法。该方法首先将语音信号编码为说话人独立(speaker independent ,SI)的特征表示,如PPG特征。之后训练WaveNet以SI为条件生成相应的时域信号。在运行时,给定语音提取的相同SI特征用于驱动WaveNet生成转换后的语音。
- 创新点: 1.在不使用参数声码器的条件下,提出的方法防止了特征与生成语音的错误匹配 2.绕过转换的中间声码器功能,所提出的方法进一步减少了WaveNet声码器最近提出的VC技术。
2 Voice Conversion With WaveNet
2.1 WaveNet Vocoder
WaveNet声码器能够将传统声码器提取的特征(非周期性特征、频谱特征、基频特征)重建为对应的时域特征。给定波形序列 x = [ x 0 , x 1 , . . . , x T ] x=[x_0,x_1,...,x_T] x=[x0,x1,...,xT],附加本地输入条件 h \bm{h} h,WaveNet声码器可以对条件分布 p ( x ∣ h ) p(x|\bm{h}) p(x∣h)进行建模:
p ( x ∣ h ) = ∏ t = 1 T p ( x t ∣ x 1 , x 2 , . . . , x t ; h ) p(x|\bm{h}) = \prod_{t=1}^Tp(x_t|x_1,x_2,...,x_t;\bm{h}) p(x∣h)=t=1∏Tp(xt∣x1,x2,...,xt;h) 为了建立长范围时间独立的语音特征,使用因果卷积和空洞卷积。第i层的残差块,门限激活函数可以如下表示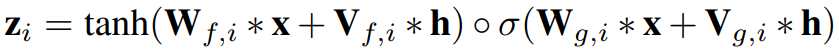
2.2 The Limitations

3 WaveNet Approach To Voice Conversion
本文研究了使用PPG作为WaveNet的本地条件输入进行无声码器语音转换的有效性,所提出的方法不依赖中间特征来进行说话者身份的转换。同时由于PPG特征时独立于说话人的,所以能够减少WaveNet声码器特征与合成出的声音不匹配的问题
 给定目标说话人的音频,提取PPGs L ∈ R D × N L\in R^{D\times N} L∈RD×N,其中 D D D为特征维度, N N N为帧数。 f 0 f_0 f0和vuv特征也被提取,其中 F 0 ∈ R 1 × N F0\in R^{1\times N} F0∈R1×N F v u v ∈ R 1 × N F_{vuv} \in R^{1\times N} Fvuv∈R1×N。为了便于WaveNet训练,扩展了PPG,f0和vuv以匹配时域信号的时间分辨率,表示为
给定目标说话人的音频,提取PPGs L ∈ R D × N L\in R^{D\times N} L∈RD×N,其中 D D D为特征维度, N N N为帧数。 f 0 f_0 f0和vuv特征也被提取,其中 F 0 ∈ R 1 × N F0\in R^{1\times N} F0∈R1×N F v u v ∈ R 1 × N F_{vuv} \in R^{1\times N} Fvuv∈R1×N。为了便于WaveNet训练,扩展了PPG,f0和vuv以匹配时域信号的时间分辨率,表示为 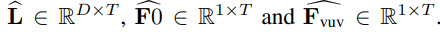 然后计算上面WaveNet公式中所提到的 h = h = h=
然后计算上面WaveNet公式中所提到的 h = h = h=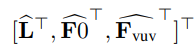 除此之外还要对 f 0 f0 f0进行线性变换,
除此之外还要对 f 0 f0 f0进行线性变换, 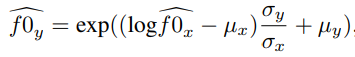 其中 μ x \mu_x μx和 σ x \sigma_x σx分别为源说话人f0的均值和方差, μ y \mu_y μy和 σ y \sigma_y σy分别为目标说话人f0的均值和方差, f 0 y ^ \widehat{f0_y} f0y 为转换后的目标说话人的f0。之后在使用WaveNet进行合成
其中 μ x \mu_x μx和 σ x \sigma_x σx分别为源说话人f0的均值和方差, μ y \mu_y μy和 σ y \sigma_y σy分别为目标说话人f0的均值和方差, f 0 y ^ \widehat{f0_y} f0y 为转换后的目标说话人的f0。之后在使用WaveNet进行合成 4 Experimental Setup
数据集使用CMU-ARCTIC(2男2女,每人使用500句训练,使用20句进行评估)。使用WORLD声码器提取513为频谱特征,1维AP和1维F0,40维的PGG使用WSJ训练后提取。所有音频的采样率为16khz。
实验结果:


5 Conclusion
本文提出了一种使用WaveNet的非并行数据的无声码器语音转换方法。 所提出的方法不依赖声码器特征进行转换,这减少了基于WaveNet声码器的方法中的特征失配问题。 实验结果表明,在保持说话人身份的同时,WaveNet-VC在质量方面明显优于基线方法。
论文地址:https://arxiv.org/abs/1902.03705
转载地址:http://xkgwb.baihongyu.com/